

Introduction
In today's fast-changing world of technology, creatives need to understand and make practical use of AI diffusion models. You can create photorealistic portraits or complex digital landscapes with just a few clicks. However, choosing the perfect model from the myriad options can be challenging.
This page explores how to use AI diffusion models, showing simple ways to take advantage of these powerful tools. By reading below, you can navigate the complexities of adopting AI. You will also find the best ways to integrate it and unlock its full potential for driving innovation and gaining a competitive edge.

In this article
Understanding AI Diffusion Models
In simple terms, Stable Diffusion models give you control over the style of your generated images. Using a model trained in real-life photos produces realistic results like photorealistic portraits, while a model trained in watercolor illustrations creates images with a painted look.
What Is the Purpose of AI Diffusion Models?
Every day, users are creating, mixing, and developing new models. With easier and faster training, models learn intricate details and nuances of specific styles. This enables training models for particular styles and purposes.
Why Are AI Diffusion Models Important?
Diffusion models have made significant strides due to advancements in machine learning techniques, abundant image data, and improved hardware. Their key differentiators from predecessors lie in their ability to generate highly realistic imagery and match real image distributions more effectively than GANs.
Unlike GANs, diffusion models are more stable and avoid mode collapse. They offer greater diversity in generated images. Additionally, you can condition diffusion models on various inputs, such as text, bounding boxes, masked images, or lower-resolution images.
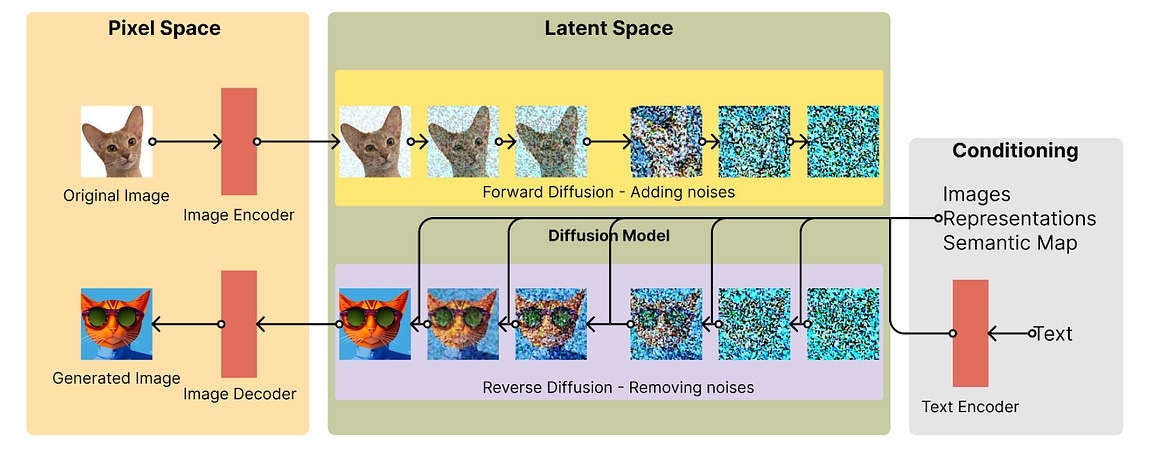
The Key Components of AI Diffusion Models
AI Diffusion Models have four main components: frame, subject, style, and your prompt/seed.
Frame
The frame determines the type of images to be generated, such as oil painting, digital illustration, or pencil drawing. It provides an overall look and feel for the image. If not specified, diffusion models default to a "picture" frame, but choosing a specific frame gives you direct control over the output.

Subject
The subject refers to the main focus of the generated images. Diffusion models excel at producing accurate representations of real-world objects based on publicly available internet data. However, limiting prompts to one or two subjects is advisable to achieve better results. Complex prompts with multiple subjects can result in unreliable or comical outputs due to the models' struggle with compositionality.

Style
The style of an image encompasses various aspects such as lighting, theme, art influence, or period. Styles like "beautifully lit," "modern cinema," or "surrealist" can significantly influence the final output. By applying different styles to a prompt, you can alter the tone and visual characteristics of the resulting images. Experimenting with different combinations of frames and styles allows for various creative possibilities.
Prompt
A prompt, or seed, combines the frame, subject, and style to create a specific instruction for generating an image. The order and phrasing of the prompt elements can affect the outcome, so it's important to experiment and refine the prompt until you achieve the desired result.
Additionally, you can use a fixed seed to produce consistent images for the same prompt. By varying the prompt or seed, you can traverse the latent space and explore different variations of the images.

Popular AI Diffusion Models at a Glance
Popular AI diffusion models have revolutionized the field of generative AI, pushing the boundaries of image synthesis and artistic creativity. Here is a brief overview of four notable models:
DALL-E 2
DALL-E 2, developed by OpenAI, is a successor to the original DALL-E model. It combines the power of diffusion models with imaginative images from textual prompts. By conditioning on textual descriptions, DALL-E 2 can produce novel and diverse visual outputs, expanding the possibilities of AI-generated art.
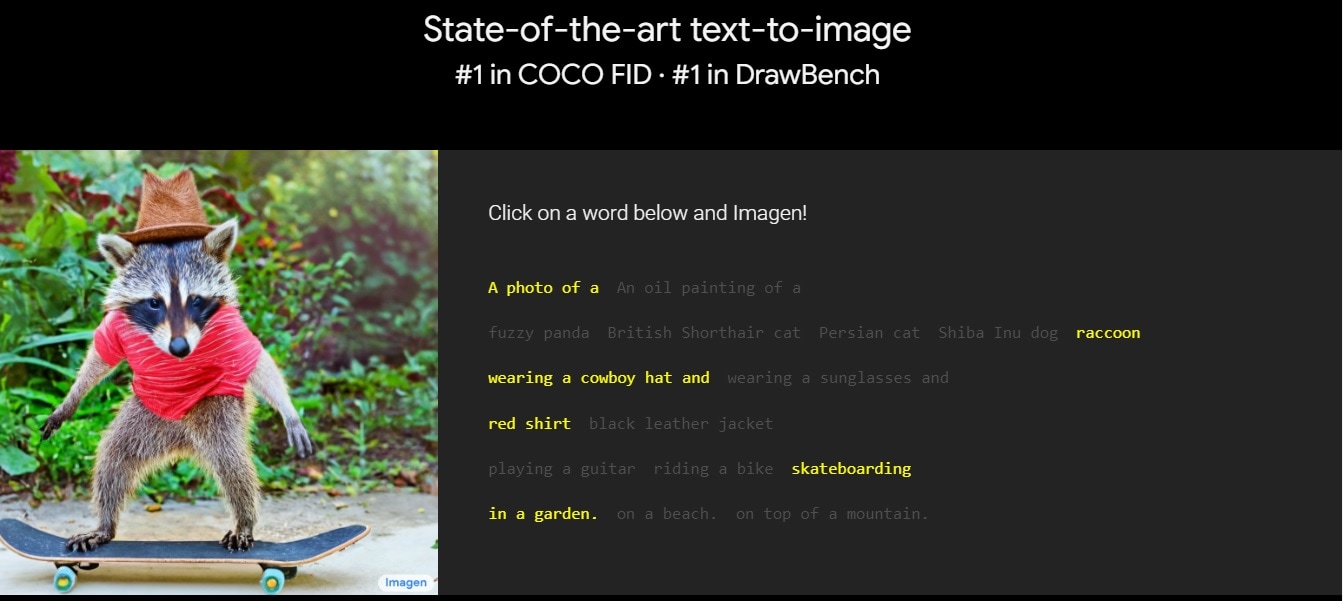
Imagen
Imagen is a versatile diffusion model that creates realistic and high-quality images. It can generate stunning visuals that closely resemble real-world scenes. Its ability to capture intricate details and nuances makes it popular for various applications.
Midjourney
Midjourney is an AI diffusion model specializing in creating impressive and engaging portraits. It uses the power of diffusion models to generate highly realistic human faces with remarkable levels of detail. Whether capturing expressions or intricate facial features, Midjourney offers a powerful tool for creatives.

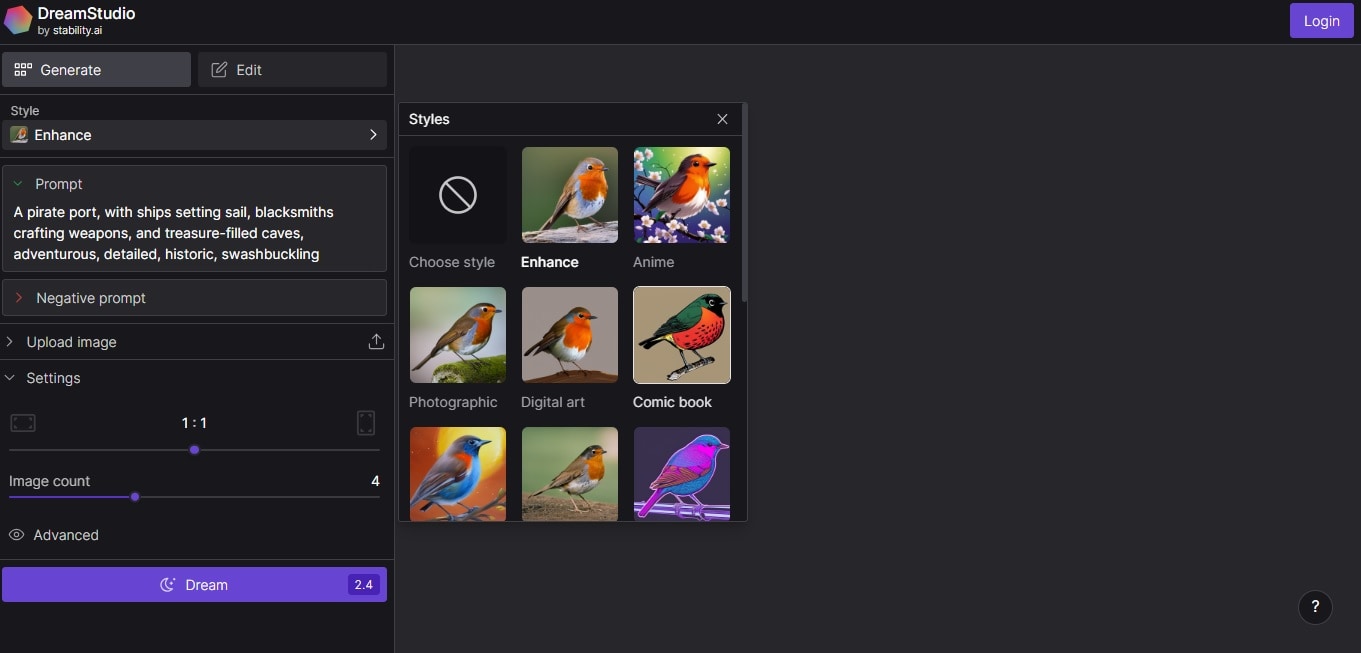
DreamStudio
DreamStudio is an AI diffusion model known for its ability to generate dream-like and surreal imagery. By manipulating the diffusion process, DreamStudio produces unique and visually striking outputs. Its results push the boundaries of traditional art. The tool offers a platform for artists and creatives to explore unconventional and imaginative styles. It can unlock new realms of artistic expression.
Current Limitations of AI Diffusion Models
While diffusion models have demonstrated impressive capabilities, they have limitations. Here are a few notable constraints to provide a comprehensive understanding.
Face Distortion
AI Diffusion models tend to introduce substantial distortion when the number of subjects in a prompt exceeds three. For instance, if the prompt involves "a family of six posing for a family photograph in their living room," the resulting image may exhibit significant facial distortions.

Text Generation
Even though AI diffusion models excel at generating images from textual prompts, they struggle with text generation within images. For example, when prompted with "a person wearing a t-shirt with the text MMM," the generated image may include words on the shirt but not necessarily the accurate word "MMM." Instead, it may display variations or even omit the text entirely. This limitation is expected to be addressed in future model iterations.

Limited Prompt Understanding
Achieving the desired output sometimes requires extensive fine-tuning and manipulation of the prompt. This process may reduce the efficiency of AI diffusion models as productivity tools, although they still provide productivity benefits.
Bonus: Booth.ai – A Brand New AI Software With Diffusion Model
Booth.ai specializes in harnessing AI's power to transform how businesses interact with customers. It enables organizations to deliver exceptional customer experiences, automate workflows, and enhance operational efficiency.
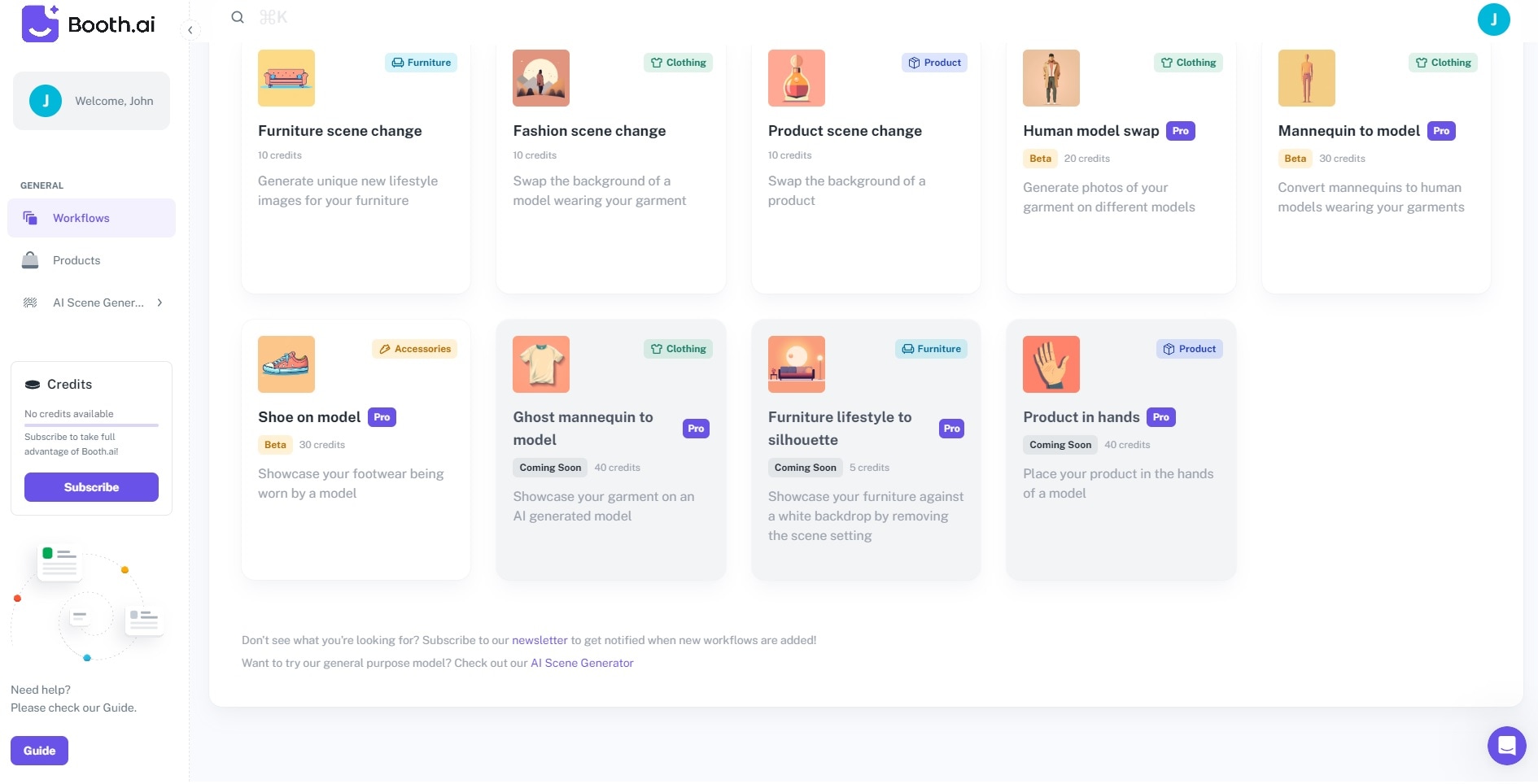
Key Features
Booth.ai is loaded with key features to kickstart your company or brand. Here are some of them below.
- AI Scene Generator. You can effortlessly create stunning lifestyle photos of your products by providing your desired shot details and uploading sample product images.
- Interactive Workflows. Booth.ai has a powerful Workflows dashboard where you can generate images for your whole product line in one window.
- Personal Photographer. You can use simple photos taken with your phone or provided by customers. Just upload the images and a description of what you envision, and Booth.ai will transform your sample product images into stunning visuals based on your preferences.
Pricing
Booth.ai offers three different price plans to suit your budget and needs.
- Tier I: $24.99/month
- Tier II: $199/month
- Tier III: $499/month
How To Create AI-Generated Images in Seconds Using Booth.ai
With only three simple steps, you can effortlessly create unique and engaging product images that capture attention using Booth AI's intuitive platform. Here are the steps below.
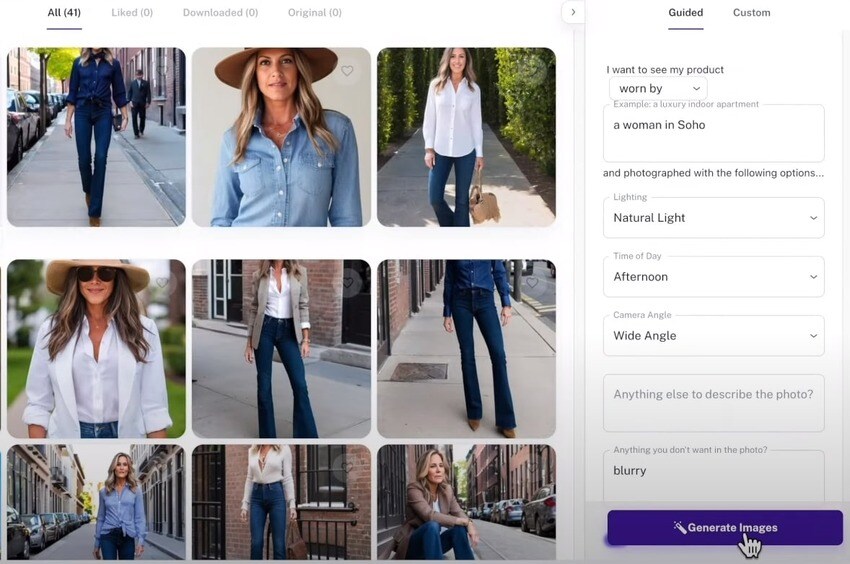
Step 1: Visit Booth.ai and log in or sign up for an account. Next, go to Workflows or AI Scene Generator to start uploading reference photos of your product.
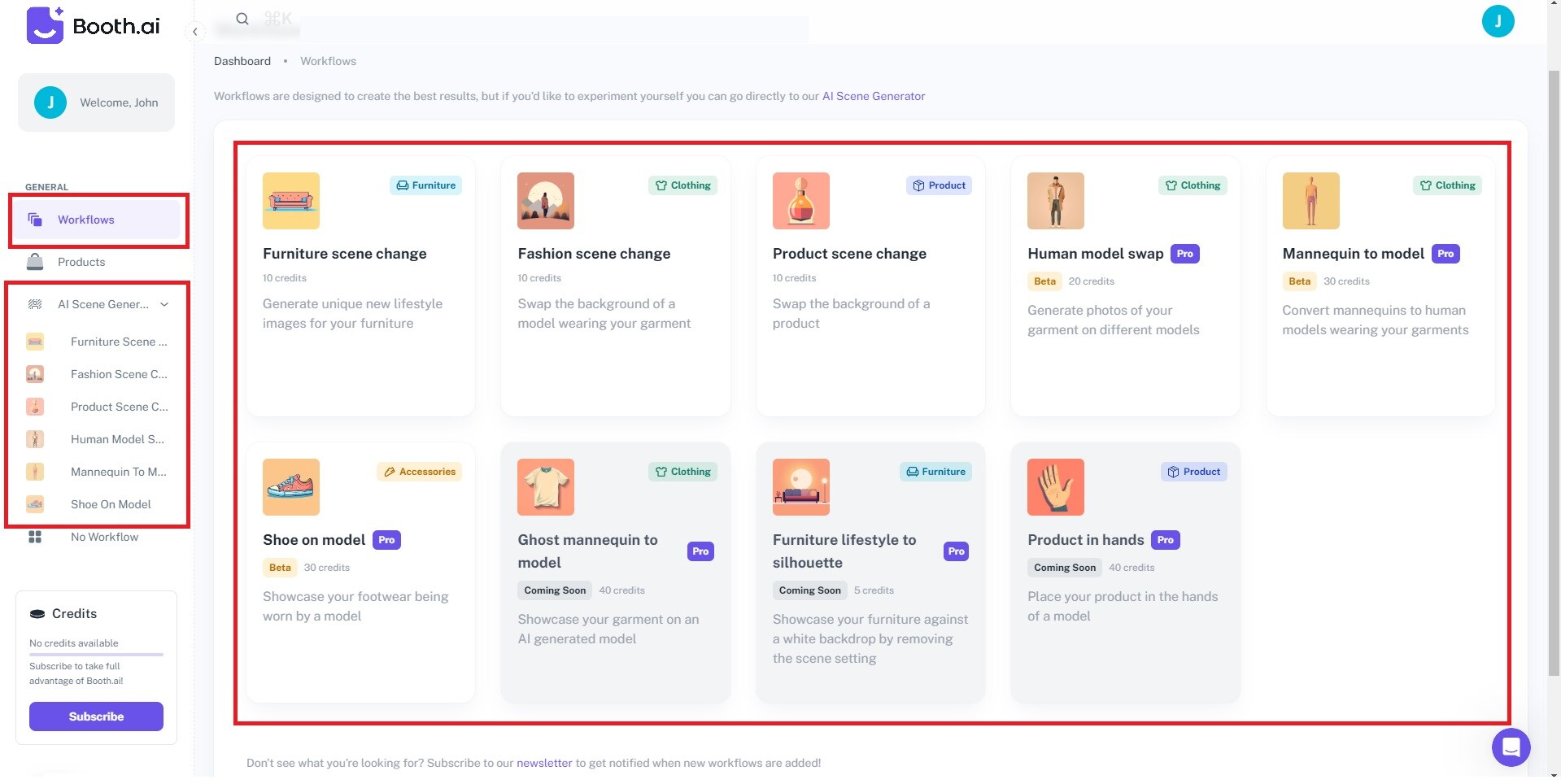
Step 2: Submit a text prompt detailing your vision on the right panel. Describe the scene and any elements you want to exclude from the photo using the provided dialog boxes. Customize the Image generation approach, Conditioning, and Product position to your preference.
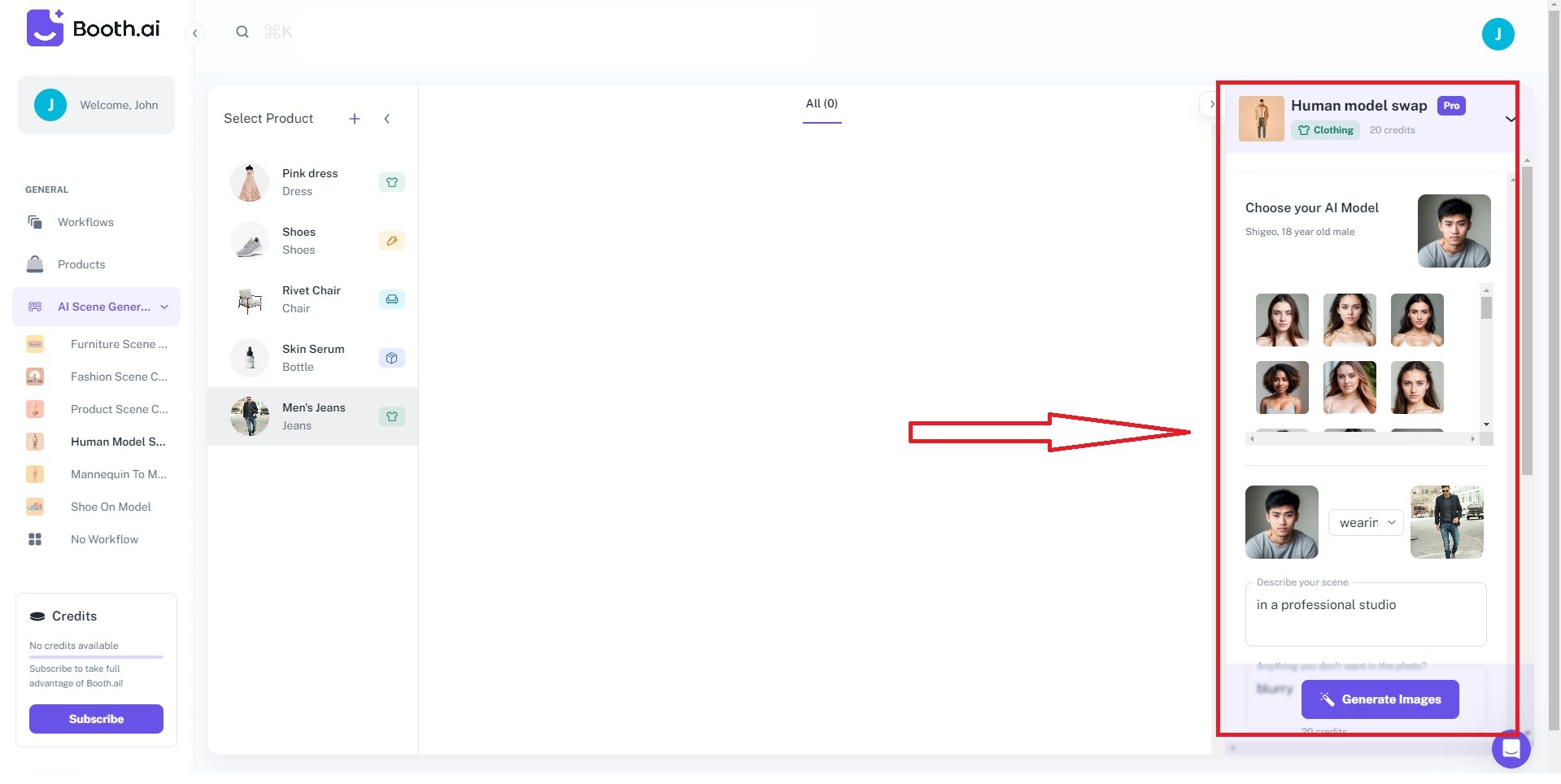
Step 3: Once you've completed your setup, click Generate Image and let Booth.ai create the perfect image you envisioned. Simply wait a few seconds and start receiving the images you want to take control of your visual storytelling with ease and precision.
Conclusion
The groundbreaking capabilities of stable diffusion models have taken the internet by storm. DALL-E2, Imagen, Midjourney, DreamStudio, and Booth.ai are powerful tools for generating highly realistic and diverse images.
These models represent the pinnacle of generative capabilities. This is due to their ability to match and even surpass the distribution of real images. Among these alternatives, Booth.ai stands out. It's an innovative option for exploring various frames, subjects, and styles. Booth.ai allows you to create unique and captivating imagery. Feel free to dive into these cutting-edge tools, unlock their potential, and embark on creative experiments.